- Getting Movistar Peru ZTE MF193 work in Debian GNU/Linux How to get Movistar Peru (Internet Móvil) ZTE 3G MF193...
- Subversion auth using SSH external key-pair Usually, when using Subversion’s SSH authentication facility, Subversion’s client will...
- s3tools – Simple Storage Service for non-Amazon providers Using s3tools to interact with a S3-compatible storage service for...
I don’t claim to be a networking expert but at least I want to think I’m well educated. After few minutes I’ve focused my efforts on dealing with the ADSL router/modem’s networking configuration. The device is provided by Movistar (formerly Telefonica) and it runs OpenRG. I’ve discovered that have the same issue and what Movistar did was basically replacing the device. Of course the problem is gone after that.
So, this post is dedicated to those who don’t give up. Following the steps below will allow SSH outbound traffic for a OpenRG-based device.
OpenRG device specs
Software Version: 6.0.18.1.110.1.52 Upgrade Release Date: Oct 7 2014
Diagnostic
When you do the command below, it shows nothing but timeout. Even when you SSH the router it doesn’t establish connection to it.
ssh -vv host.somewhere.com
Solution
Change router’s SSH service port.
This step will allow you to access the console-based configuration for the router (since I haven’t found any way to do the steps described below from the web management interface).
To do so, go to System > Management > SSH. Update the service port to something else than 22, for instance 2222.
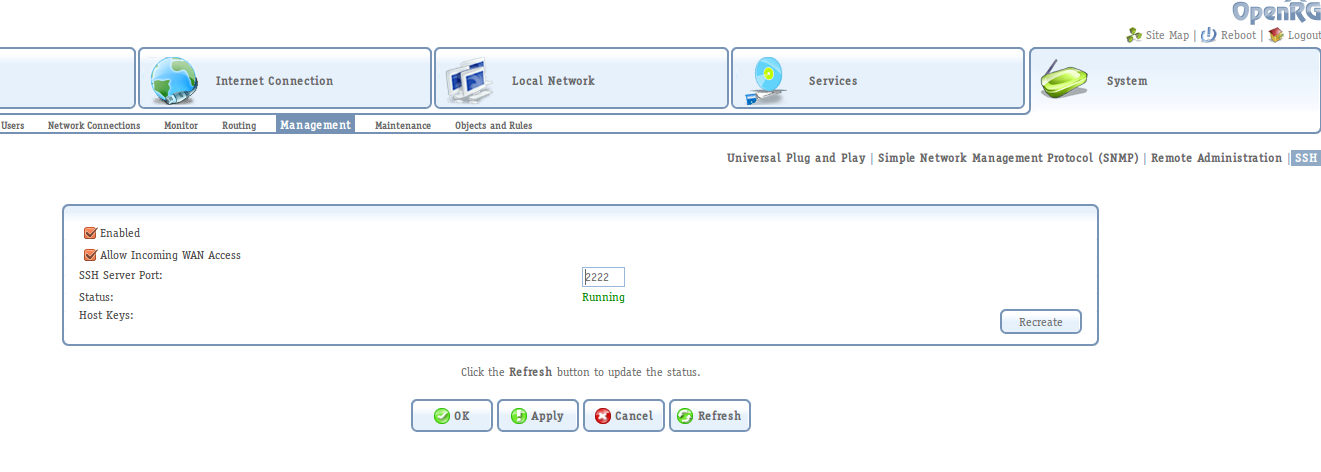
Connect to the SSH interface
Once you have changed the SSH service port, you can access it from a SSH client.
ssh -p 2222 [email protected] [email protected]'s password: OpenRG>
Once you have the console prompt, issue the following commands to allow SSH outbound traffic coming from the LAN and Wifi networks. After the last command, which saves and updates the device’s configuration, you should be able to do SSH from any computer in your network to the Internet (thanks to ).
OpenRG> conf set fw/policy/0/chain/fw_br0_in/rule/0/enabled 0 Returned 0 OpenRG> conf set fw/policy/0/chain/fw_br1_in/rule/0/enabled 0 Returned 0 OpenRG> conf reconf 1 Returned 0]]>
- Getting Movistar Peru ZTE MF193 work in Debian GNU/Linux How to get Movistar Peru (Internet Móvil) ZTE 3G MF193...
What the above statement means for developers or data scientists is that you can “talk” SQL to your HBase cluster. Sounds good right? Setting up Phoenix on Cloudera CDH can be really frustrating and time-consuming. I wrapped-up references from across the web with my own findings to have both play nice.
Building Apache Phoenix
Because of dependency mismatch for the pre-built binaries, supporting Cloudera’s CDH requires to build Phoenix using the versions that match the CDH deployment. The CDH version I used is CDH4.7.0. This guide applies for any version of CDH4+.
Note: You can find CDH components version in the “CDH Packaging and Tarball Information” section for the “Cloudera Release Guide”. Current release information (CDH5.2.1) is available in this .
Preparing Phoenix build environment
Phoenix can be built using maven or gradle. General instructions can be found in the “” webpage.
Before building Phoenix you need to have:
- JDK v6 (or v7 depending which CDH version are you willing to support)
- Maven 3
- git
Checkout correct Phoenix branch
Phoenix has two major release versions:
- 3.x – supports HBase 0.94.x (Available on CDH4 and previous versions)
- 4.x – supports HBase 0.98.1+ (Available since CDH5)
Clone the Phoenix git repository
git clone https://github.com/apache/phoenix.git
Work with the correct branch
git fetch origin git checkout 3.2
Modify dependencies to match CDH
Before building Phoenix, you will need to modify the dependencies to match the version of CDH you are trying to support. Edit phoenix/pom.xml and do the following changes:
Add Cloudera’s Maven repository
+ <repository> + <id>cloudera</id> + https://repository.cloudera.com/artifactory/cloudera-repos/ + </repository>
Change component versions to match CDH’s.
- <hadoop-one.version>1.0.4</hadoop-one.version> - <hadoop-two.version>2.0.4-alpha</hadoop-two.version> + <hadoop-one.version>2.0.0-mr1-cdh4.7.0</hadoop-one.version> + <hadoop-two.version>2.0.0-cdh4.7.0</hadoop-two.version> <!-- Dependency versions --> - <hbase.version>0.94.19 + <hbase.version>0.94.15-cdh4.7.0 <commons-cli.version>1.2</commons-cli.version> - <hadoop.version>1.0.4 + <hadoop.version>2.0.0-cdh4.7.0 <pig.version>0.12.0</pig.version> <jackson.version>1.8.8</jackson.version> <antlr.version>3.5</antlr.version> <log4j.version>1.2.16</log4j.version> <slf4j-api.version>1.4.3.jar</slf4j-api.version> <slf4j-log4j.version>1.4.3</slf4j-log4j.version> - <protobuf-java.version>2.4.0</protobuf-java.version> + <protobuf-java.version>2.4.0a</protobuf-java.version> <commons-configuration.version>1.6</commons-configuration.version> <commons-io.version>2.1</commons-io.version> <commons-lang.version>2.5</commons-lang.version>
Change target version, only if you are building for Java 6. CDH4 is built for JRE 6.
<artifactId>maven-compiler-plugin</artifactId> <version>3.0</version> <configuration> - <source>1.7</source> - <target>1.7</target> + <source>1.6</source> + <target>1.6</target> </configuration>
Phoenix building
Once, you have made the changes you are set to build Phoenix. Our CDH4.7.0 cluster uses Hadoop 2, so make sure to activate the hadoop2 profile.
mvn package -DskipTests -Dhadoop.profile=2
If everything goes well, you should see the following result:
[INFO] ------------------------------------------------------------------------ [INFO] Reactor Summary: [INFO] [INFO] Apache Phoenix .................................... SUCCESS [2.729s] [INFO] Phoenix Hadoop Compatibility ...................... SUCCESS [0.882s] [INFO] Phoenix Core ...................................... SUCCESS [24.040s] [INFO] Phoenix - Flume ................................... SUCCESS [1.679s] [INFO] Phoenix - Pig ..................................... SUCCESS [1.741s] [INFO] Phoenix Hadoop2 Compatibility ..................... SUCCESS [0.200s] [INFO] Phoenix Assembly .................................. SUCCESS [30.176s] [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 1:02.186s [INFO] Finished at: Mon Dec 15 13:18:48 PET 2014 [INFO] Final Memory: 45M/1330M [INFO] ------------------------------------------------------------------------
Phoenix Server component deployment
Since Phoenix is a JDBC layer on top of HBase a server component has to be deployed on every HBase node. The goal is to have Phoenix server component added to HBase classpath.
You can achieve this goal either by copying the server component directly to HBase’s lib directory, or copy the component to an alternative path then modify HBase classpath definition.
For the first approach, do:
cp phoenix-assembly/target/phoenix-3.2.3-SNAPSHOT-server.jar /opt/cloudera/parcels/CDH/lib/hbase/lib/
Note: In this case CDH is a synlink to the current active CDH version.
For the second approach, do:
cp phoenix-assembly/target/phoenix-3.2.3-SNAPSHOT-server.jar /opt/phoenix/
Then add the following line to /etc/hbase/conf/hbase-env.sh
/etc/hbase/conf/hbase-env.sh export HBASE_CLASSPATH_PREFIX=/opt/phoenix/phoenix-3.2.3-SNAPSHOT-server.jar
Wether you’ve used any of the methods, you have to restart HBase. If you are using Cloudera Manager, restart the HBase service.
To validate that Phoenix is on HBase class path, do:
sudo -u hbase hbase classpath | tr ':' '\n' | grep phoenix
Phoenix server validation
Phoenix provides a set of client tools that you can use to validate the server component functioning. However, since we are supporting CDH4.7.0 we’ll need to make few changes to such utilities so they use the correct dependencies.
phoenix/bin/sqlline.py:
sqlline.py is a wrapper for the JDBC client, it provides a SQL console interface to HBase through Phoenix.
index f48e527..bf06148 100755 --- a/bin/sqlline.py +++ b/bin/sqlline.py @@ -53,7 +53,8 @@ colorSetting = "true" if os.name == 'nt': colorSetting = "false" -java_cmd = 'java -cp "' + phoenix_utils.hbase_conf_path + os.pathsep + phoenix_utils.phoenix_client_jar + \ +extrajars="/opt/cloudera/parcels/CDH/lib/hadoop/lib/commons-collections-3.2.1.jar:/opt/cloudera/parcels/CDH/lib/hadoop/hadoop-auth-2.0.0-cdh4.7.0.jar:/opt/cloudera/parcels/CDH/lib/hadoop/hadoop-common-2.0.0-cdh4.7.0.jar:/opt/cloudera/parcerls/CDH/lib/oozie/libserver/hbase-0.94.15-cdh4.7.0.jar" +java_cmd = 'java -cp ".' + os.pathsep + extrajars + os.pathsep + phoenix_utils.hbase_conf_path + os.pathsep + phoenix_utils.phoenix_client_jar + \ '" -Dlog4j.configuration=file:' + \ os.path.join(phoenix_utils.current_dir, "log4j.properties") + \ " sqlline.SqlLine -d org.apache.phoenix.jdbc.PhoenixDriver \
phoenix/bin/psql.py:
psql.py is a wrapper tool that can be used to create and populate HBase tables.
index 34a95df..b61fde4 100755 --- a/bin/psql.py +++ b/bin/psql.py @@ -34,7 +34,8 @@ else: # HBase configuration folder path (where hbase-site.xml reside) for # HBase/Phoenix client side property override -java_cmd = 'java -cp "' + phoenix_utils.hbase_conf_path + os.pathsep + phoenix_utils.phoenix_client_jar + \ +extrajars="/opt/cloudera/parcels/CDH/lib/hadoop/lib/commons-collections-3.2.1.jar:/opt/cloudera/parcels/CDH/lib/hadoop/hadoop-auth-2.0.0-cdh4.7.0.jar:/opt/cloudera/parcels/CDH/lib/hadoop/hadoop-common-2.0.0-cdh4.7.0.jar:/opt/cloudera/parcerls/CDH/lib/oozie/libserver/hbase-0.94.15-cdh4.7.0.jar" +java_cmd = 'java -cp ".' + os.pathsep + extrajars + os.pathsep + phoenix_utils.hbase_conf_path + os.pathsep + phoenix_utils.phoenix_client_jar + \ '" -Dlog4j.configuration=file:' + \ os.path.join(phoenix_utils.current_dir, "log4j.properties") + \ " org.apache.phoenix.util.PhoenixRuntime " + args
After you have done such changes you can test connectivity by issuing the following commands:
./bin/sqlline.py zookeeper.local Setting property: [isolation, TRANSACTION_READ_COMMITTED] issuing: !connect jdbc:phoenix:zookeeper.local none none org.apache.phoenix.jdbc.PhoenixDriver Connecting to jdbc:phoenix:zookeeper.local 14/12/16 19:26:10 WARN conf.Configuration: dfs.df.interval is deprecated. Instead, use fs.df.interval 14/12/16 19:26:10 WARN conf.Configuration: hadoop.native.lib is deprecated. Instead, use io.native.lib.available 14/12/16 19:26:10 WARN conf.Configuration: fs.default.name is deprecated. Instead, use fs.defaultFS 14/12/16 19:26:10 WARN conf.Configuration: topology.script.number.args is deprecated. Instead, use net.topology.script.number.args 14/12/16 19:26:10 WARN conf.Configuration: dfs.umaskmode is deprecated. Instead, use fs.permissions.umask-mode 14/12/16 19:26:10 WARN conf.Configuration: topology.node.switch.mapping.impl is deprecated. Instead, use net.topology.node.switch.mapping.impl 14/12/16 19:26:11 WARN conf.Configuration: fs.default.name is deprecated. Instead, use fs.defaultFS 14/12/16 19:26:11 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 14/12/16 19:26:12 WARN conf.Configuration: fs.default.name is deprecated. Instead, use fs.defaultFS 14/12/16 19:26:12 WARN conf.Configuration: fs.default.name is deprecated. Instead, use fs.defaultFS Connected to: Phoenix (version 3.2) Driver: PhoenixEmbeddedDriver (version 3.2) Autocommit status: true Transaction isolation: TRANSACTION_READ_COMMITTED Building list of tables and columns for tab-completion (set fastconnect to true to skip)... 77/77 (100%) Done Done sqlline version 1.1.2 0: jdbc:phoenix:zookeeper.local>
Then, you can either issue SQL-commands or Phoenix-commands.
0: jdbc:phoenix:zookeeper.local> !tables +------------------------------------------+------------------------------------------+------------------------------------------+---------------------------+ | TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | +------------------------------------------+------------------------------------------+------------------------------------------+---------------------------+ | null | SYSTEM | CATALOG | SYSTEM TABLE | | null | SYSTEM | SEQUENCE | SYSTEM TABLE | | null | SYSTEM | STATS | SYSTEM TABLE | | null | null | STOCK_SYMBOL | TABLE | | null | null | WEB_STAT | TABLE | +------------------------------------------+------------------------------------------+------------------------------------------+---------------------------+]]>
- No SSH for you – how to fix OpenRG routers I find interesting when faced a taken-for-granted situation, in particular...
- GNU no es Unix Se aproximaba el final del año 1996 u 1997 cuando...
- Compute clusters for Debian development and building – final report Compute clusters for Debian development and building – final report...
Trying different combinations for wvdial.conf was no heaven for sure, but I’ve found this wonderful from Vienna, Austria! that really made a difference. Of course he’s talking about the model MF180 but you get the idea. So I’m sharing what was different for the MF193.
Basically, I’ve done the eject and disable CD-ROM thing already, but still no progress. I’ve also tried using wvdial to send AT commands to the evasive /dev/ttyUSBX device. Starting from scratch confirmed that I’ve done such things properly indeed. I was amused by the fact that I could use screen to talk to the modem! (yo, all the time wasted trying to have minicom and friends play nice)
So, let’s get to the point. After following this procedure, you should be able to use NetworkManager to connect to the Interwebs using the 3G data service from Movistar Peru.
- Step 1 – follow the guide
- Step 2 – Here I had to use
/dev/ttyUSB4 - Step 3 – follow the guide
- Unplug your USB modem
- Plug your USB modem. This time you should see only
/dev/ttyUSB{0,1,2}and/dev/gsmmodemshould be missing (not sure if this is a bug). Now/dev/ttyUSB2is your guy. - Step 4 – use
/dev/ttyUSB2 - Run
wvdialfrom CLI – it should connect successfully. - Stop
wvdial - Select the Network icon on GNOME3, click on the Mobile Broadband configuration you have, if not create one.
- Voilá. Happy surfing!
I’m pasting my wvdial.conf, just in case.
[Dialer Defaults] Modem = /dev/ttyUSB2 Username = movistar@datos Password = movistar APN = movistar.pe Phone = *99# Stupid Mode = 1 Init2 = AT+CGDCONT=4,"IP","movistar.pe"]]>
- Too open stack Reflections about the OpenStack governance and development model and how...
- debian – fostering innovation Latest months have been of great improvement and empowerment on...
- FLISOL Puno Past Saturday April 28 I attended to the FLISOL 2012...
Turns out that I did like this new so called GNOME3, the non-window based but an application-based system (that is something that sticks in my head). I liked the way it makes sense as a desktop system, like when you look for applications, documents, connect to networks, use pluggable devices or just configure stuff every time with less and less effort. Good practices and concepts learned from Mac OS X-like environments and for sure taking advantage of the new features the Linux kernel and user-space environment got over the years. So, like one month later I stick with it and it makes sense for me to keep it. I had no chance to try the latest XFCE or KDE, my default choices before this experience. Kudos GNOME team, even after the depictions you guys had on GNOME Shell; as I learned.
This whole situation got me into some pondering about the past of the Linux user experience and how we in the community lead people into joining. I remember that when I guy asked: how do I configure this new monitor/VGA card/network card/Etc? the answer was in the lines of: what is the exact chipset model and specific whole product code number that your device has? Putting myself in the shoes of such people or today’s people I’d say: what are you talking about? what it is a chipset? I mean, like it was too technical that only one guy with more than average knowledge could grasp. From a product perspective this is similar for a car manufacturer tell to a customer to look for the exact layout or design your car’s engine has, so that they are able to tell whether is the 82’s model A or 83’s model C. Simplicity on naming and identification was not in the mindset of most of us.
This is funny because as technology advances it also becomes more transparent to the customer. So, for instance, today’s kids can become really power users of any new technology as if they had, indeed, many pre-set chipsets in their brain. But when going into the details we had to grasp few years ago they have some hard time figuring out the complexity of the product that presents itself on this clean and simple interface. New times, interesting times. Always good to look back. No, I’m not getting old.
]]>- GSoC 2011: Compute Clusters Integration for Debian Development and Building Hi, been offline for a while and now after my...
- Subversion auth using SSH external key-pair Usually, when using Subversion’s SSH authentication facility, Subversion’s client will...
- DebianPeru Hello, this is just a quick post to announce some...
Update: I no longer use this key. Instead I’ve to a new key: D562EBBE.
A bit late but I’ve created a . I’ve published a as well. I hope I can meet fellow Debian developers soon to get my new key signed. So, if you are in town (Arequipa, Peru) drop me an email!
]]>
- GSoC 2011: Compute Clusters Integration for Debian Development and Building Hi, been offline for a while and now after my...
- s3tools – Simple Storage Service for non-Amazon providers Using s3tools to interact with a S3-compatible storage service for...
- Compute clusters for Debian development and building – final report Compute clusters for Debian development and building – final report...
I’ve been using Heroku for a while to deploy small to medium size projects. I liked the tools and developer-centered experience they offer. Openshift is quite new on the market and it comes in two flavors: , which is a PaaS service, and Openshift Enterprise, which allows organization to setup a PaaS within their own infrastructure. Both of them powered by the software. I’ll not compare Heroku vs. Openshift feature by feature but from my experience I can tell that Openshift is far from mature and will need to give developers more features to increase adoption.
When developing applications for Openshift developers are given a set of application stack components, similar to Heroku’s buildpacks. They call them cartridges. You can think of them as operating system packages, since the idea is the same: have a particular application stack component ready to be used by application developers. Most of the cartridges offered by the service are base components such as application server, programming language interpreters (Ruby, Python, etc), web development frameworks and data storage, such as relational and non-relational databases. Cartridges are installed inside a gear, which is a sort of application container (I believe it uses LXC internally). Unsurprisingly this Openshift component doesn’t leverage on existing packaging for RHEL 64bit, the OS that powers the service. I’d expect such things from the RedHat ecosystem.
I had to develop a cartridge to have a particular BI engine to be used as embed component by application developers. After reading I realized this can be piece of cake, since I have packaging experience. Wrong. Well, quite so. The tricky part for Openshift Online is that it does not offer enough information on the cartridge install process so you can see what’s going wrong. To be able to see more details on the process you’ll need to setup an Openshift origin server and use it as a testing facility. Turns out that having a Origin server to operate correctly is also a and consumed a lot of my time. Over the recent weeks I’ve learned from origin developers that such features are on the road map for the upcoming releases. That’s good news.
One of the challenges I had, and still have to figure out, is that unlike the normal cartridges mine didn’t required to launch any service. Since it is a BI engine I just needed to configure and deploy to an application server such as JBoss. Cartridge format requires to have a sort of service init.d script under bin along with setup, install and configuration scripts that are ran on install. Although every day I become more familiar with origin and Openshift internals I still have work to do. Nice thing is that I was already familiar with LXC and Ruby-based applications so I could figure where things are placed and where to look for errors on origin quite easily. The cartridges are on my if you care to take a look and offer advice.
]]>- No SSH for you – how to fix OpenRG routers I find interesting when faced a taken-for-granted situation, in particular...
- svn changelist tutorial It is not unusual that I’ve come upon the situation...
- New GPG Key 65F80A4D Update: I no longer use this key. Instead I’ve transitioned...
$HOME/.ssh. However, there could be situations when you’ll need to use a different key-pair. In such situations you can use a nice trick to have svn+ssh authentication work smoothly.
Let’s say you have an external key-pair, the public key is already configured on the Subversion server. You have the private key stored somewhere in your home directory. Now when issuing a svn checkout you’ll find that you will need some sort of SSH’s -i parameter to tell svn to use your external key-pair for authentication. Since there is not way to instruct Subversion’s client to do so, you’ll need to use a system environment variable.
Subversion makes your life easier by providing the $SVN_SSH environment variable. This variable allows you to put the ssh command and modifiers that fit your authentication needs. For our external key-pair use case, you can do something like:
export SVN_SSH="ssh -i </path/to/external-key>"
Now, next time you use Subversion svn+ssh authentication facility, the client will read $SVN_SSH and instance a ssh tunnel using the parameters you have defined. Once it has successfully authenticated you can use Subversion commands such as checkout, commit, etc in the same fashion you would normally do.
svn co svn+ssh://[email protected]/repo/for/software
Alternatives
Jeff Epler offered great advice with a more flexible approach using .ssh/config and key-pairs based on hostname.
Host svn.example.com IdentityFile %d/.ssh/id_rsa-svn.example.com Host svn2.coder.com IdentityFile %d/.ssh/id_rsa-svn2.coder.com]]>
- Building non-service cartridges for RedHat Openshift Cloud is passing the hype curve and we are seeing...
- svn changelist tutorial It is not unusual that I’ve come upon the situation...
- New GPG Key 65F80A4D Update: I no longer use this key. Instead I’ve transitioned...
Amazon, as one of the pioneers, made a good choice on their offering design by making their API implementation public. Now, vendors such as Eucalyptus private/hybrid cloud offering and many other providers can leverage and build upon the specs to offer compatible services removing the hassle for their customers to learn a new technology/tool.
I’ve bare-metal servers siting on data-center. A couple of months ago I’ve learned about their new cloud storage offering. Since I’m working a lot on cloud lately, I checked the service. It’s was nice to learn they are not re-inventing the wheel but instead implementing Amazon’s Simple Storage Service (S3) defacto standard for cloud storage.
Currently there are many S3-compatible tools available both FLOSS and freeware/closed source (). I’ve been using , which is already available in the Debian archive, to interact with S3-compatible services. Usage is pretty straightforward.
For my use case I intend to store copies of certain files on my provider’s S3-compatible service. Before being able to store files I’ll need to create buckets. If you are not very familiar with S3 terminology buckets can be seen as containers or folders (in the desktop paradigm).
First thing to do is configure your keys and credentials for accessing S3 from your provider. I do recommend to use the --configure option to create the $HOME/.s3cfg file because it will fill in all the available options for a standard S3 service, leaving you the work of just tweaking them based on your needs. You can go and create the file all by yourself if you prefer, of course.
$ sudo aptitude install s3cmd $ s3cmd --configure Enter new values or accept defaults in brackets with Enter. Refer to user manual for detailed description of all options. Access key and Secret key are your identifiers for Amazon S3 Access Key: ...
You’ll be required to enter the access key and the secret key. You’ll be asked for a encryption password (use only if you plan to use this feature). Finally, the software will test the configuration against Amazon’s service. Since this is not our case it will fail. Tell the configuration instead to not retry configuration and say Y to Save configuration.
Now, edit the $HOME/.s3cfg file and set the address for your private/third-party S3 provider. This is done here:
host_base = s3.amazonaws.com host_bucket = %(bucket)s.s3.amazonaws.com
Change s3.amazonaws.com to your provider’s address and the host_bucket configuration also. In my case I had to use:
host_base = rs1.connectria.com host_bucket = %(bucket)s.rs1.connectria.com
Now, save the file and test the service by listing the available buckets (of course there is none yet).
$ s3cmd ls
If you don’t get an error then the tool is properly configured. Now you can create buckets, put files, list, etc.
$ s3cmd mb s3://testbucket Bucket 's3://testbucket/' created $ s3cmd put testfile.txt s3://testbucket testfile.txt -> s3://testbucket/testfile.txt [1 of 1] 8331 of 8331 100% in 1s 7.48 kB/s done $ s3cmd ls s3://testbucket 2012-12-26 22:09 8331 s3://testbucket/testfile.txt]]>
Error: SSL_read:: pkcs1 padding too shortDebugging both on the agent and master sides didn’t offered much information.
On the master:
puppet master --no-daemonize --debug
On the agent:
puppet agent --test --debug
Although I had my master using 3.0.1 and the tested agent using 2.7, the problem didn’t look related to that. People @ #puppet also haven’t seen this error before.
I figured the problem reduced to an issue with openssl. So, I checked versions and there I got! agent’s openssl is using version 1.0.0j-1.43.amzn1 and master’s was using openssl-0.9.8b-10.el5_2.1 So I upgraded master’s openssl to openssl.i686 0:0.9.8e-22.el5_8.4 and voilá, the problem is gone.
I learned that there has been a in OpenSSL’s VCS that is apparently related to the issue. Hope this helps if you got into the described situation.
]]>- Compute Clusters Integration for Debian Development and Building – Report 4 Hello, this is the fourth report for the project. First,...
- Compute Clusters Integration for Debian Development and Testing – Report 3 Hello this is the third report regarding my project. As...
The usual approach would be to implement those algorithms, call them in main() and see the results. A more interesting approach would be to write a validator for each function and print whether the result is correct or not.
Since both are boring and break the rule of DRY, I’ve decided to go complicated but productive, so I’ve implemented a function testing method using function pointers that will allow me to write a single function and use it to test the algorithms using different input and expected results.
Let’s say I have 3 algorithms that implement Modular Exponentiation.
uint64 modexp1new(const uint64 &a, const uint64 &_p, const uint64 &n){
...
}
uint64 modexp2(const uint64 &_a, const uint64 &_p, const uint64 &_n){
...
}
uint64 modexp3(const uint64 &a, const uint64 &p, const uint64 &n){
...
}
If you are not familiar with the syntax, const means that the parameter is constant, thus it will not be modified inside the function. The & means that the parameter is passed as a reference, read the memory address of the calling variable, so we don’t overload fill the RAM with new variables new copies of the variables.
Now, the testing part. For my very own purposes I just want to test those particular functions and know whether if the result they output conforms what I do expect. Some people call this unit testing.
I do also want to test it in different scenarios, meaning input and output.
So, I’m creating a function that will get the three parameters required to call the functions, and a fourth parameter that is the value I do expect to be the correct answer.
Now, since I don’t want to repeat myself writing a call for each case, I’m going to create a function pointer that is an array and has the function’s address as their value. That way I can call them in a loop, and voila! we are done.
Finally, after calling the function I check the result with the expected value and print an OK or FAIL.
Tricky part for this could be understanding the function pointer. Two things to consider: the returning value from the referenced functions has to be the same for all. Second: the input definition for each function has to be similar too. This is important because function pointers are just pointers and they need to know the size of the data type in order to navigate the memory.
For this sample code the uint64 is a typedef for long long, of course. Full code is below.
void testAlgos(const uint64 &a, const uint64 &e, const uint64 &n, const uint64 &r){
uint64 (*fP[3])(const uint64&, const uint64&, const uint64&) = { &modexp1new, &modexp2, &modexp3 };
uint64 t;
for(int i=0; i<3; i++){
t = fP[i](a, e, n);
std::cout < < "F(" << i << ") " << t << "\t";
if (t == r){
std::cout << "OK";
} else {
std::cout << "FAIL";
}
std::cout << std::endl;
}
}
Now that I have this, I can use it in main this way.
int main(){
uint64 a = 3740332;
uint64 e = 44383;
uint64 n = 3130164467;
uint64 r = 1976425102;
testAlgos(a, e, n, r);
a = 404137263;
r = 2520752541;
testAlgos(a, e, n, r);
a = 21;
e = 3;
n = 1003;
r = 234;
testAlgos(a, e, n, r);
return 0;
}
Resulting in:
F(0) 657519405 FAIL F(1) 1976425102 OK F(2) 657519405 FAIL F(0) -2752082808 FAIL F(1) 2520752541 OK F(2) -2752082808 FAIL F(0) 234 OK F(1) 234 OK F(2) 234 OK
I’m happy about not having to write tests like this for all use cases:
std::cout < < "f1: " << modexp1new(a, e, n) << std::endl; std::cout << "f2: " << modexp2(a, e, n) << std::endl; std::cout << "f3: " << modexp3(a, e, n) << std::endl;
Now, happiness can be more exciting if I do use templates so I can test any function independent of the data type for the returning and input values. You know, more abstraction. Homework if time allows! Have fun!
]]>